In this short tutorial, you’ll learn how to create a database with US COVID data that you can later analyze with your favorite analytics or data science tool. You’ll also be able to refresh the COVID data by invoking one command-line statement. The whole process won’t take you more than 5 minutes.
In this tutorial, we’ll use SQLite database, but you can easily do the same steps with Postgres, MySQL, or Snowflake.
Install dbd
First, you need to install the dbd tool that we’ll use for the database creation and loading.
python3 -m venv dbd-env
source dbd-env/bin/activate
pip3 install dbdCreate dbd project
This command-line statement creates a new dbd project with an example content that we can use.
dbd init covid19
cd covid19
dbd run .A new SQLite database states.dbis created after executing the last
dbd run .
command. The database contains the following tables:

The database has been created from the model directory.

The three CSV files have been directly loaded to the SQLite database. The data stored in the us_states table are generated from the SQL SELECT stored in the us_states.sql file.

The us_states.yaml file is used for configuration of the us_states table (e.g. column data type, primary key, etc.)

Adding COVID data
We’ll use the NY Times COVID-19 data repository for getting fresh COVID data. We’ll start with a simple statistic that shows daily cases and deaths by US states. The data are in the us_states.csv file. Github provides the raw URL that points directly to this file.
https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-states.csv
The only thing you need to do is to copy this raw URL to a new us_covid.ref file that we create in the model directory of your project.
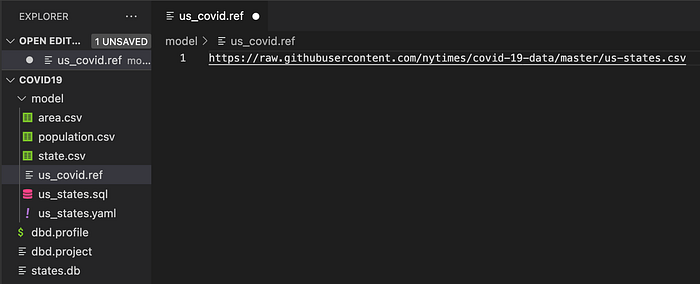
Then you can re-run the dbd from the covid19 directory:
cd covid19
dbd run .This will create a new us_covid table in the target database.
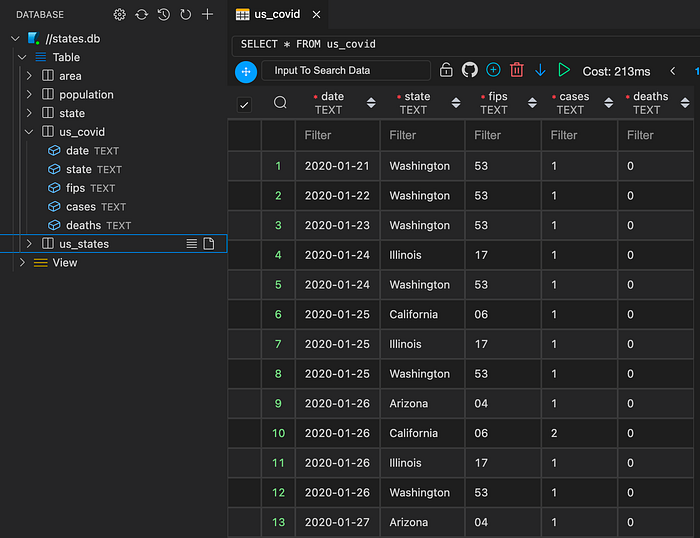
As we haven’t created any yaml file with additional configuration, dbd have used the defaults and typed all columns as TEXT . It would be nice to configure the table but we won’t need it now.
Putting data together
The last step is to join the new us_covid data to the existing us_states table. You can simply do it by adding a new us_states_covid.sql file with the SQL statement below to the model directory.
SELECT
us_covid.date AS date,
us_states.state_code,
us_states.state_name,
us_states.state_population,
us_states.state_area_sq_mi,
us_covid.cases AS state_covid_cases,
us_covid.deaths AS state_covid_deaths
FROM us_covid
JOIN us_states ON us_states.state_name = us_covid.stateWe’ll now re-run the dbd command again:
cd covid19
dbd run .There is now a new us_states_covid table in the database.
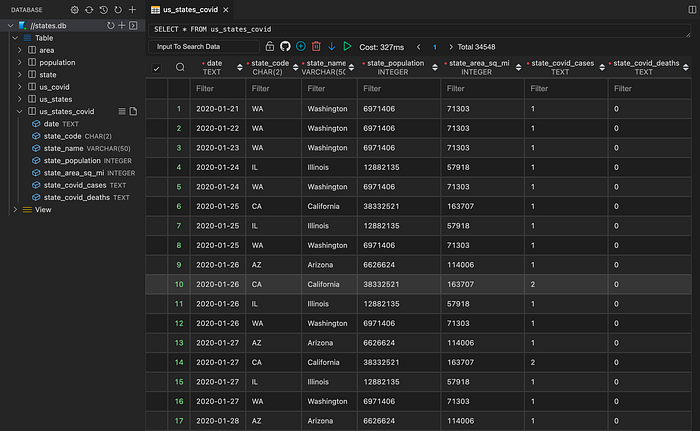
us_states_covid tableThis is all great, but the date, state_covid_cases , and state_covid_deaths columns have the default TEXT datatype.
Now is the time to provide the additional YAML configuration for the new us_states_covid table.
Let's create a new us_states_covid.yaml file with the following content:
table:
columns:
date:
type: DATE
state_covid_cases:
type: INTEGER
state_covid_deaths:
type: INTEGERand re-run the dbd command for the last time:
cd covid19
dbd run .Now the data types are fixed.
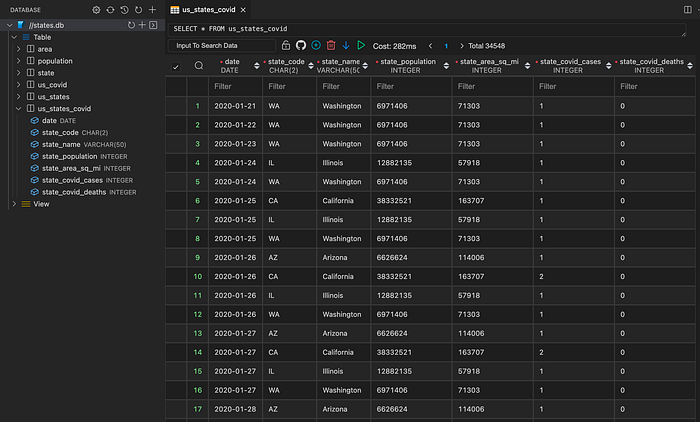
You can use an analytics or data science tool of your choice to connect to your new database and plot a few nice charts and dashboards! I can recommend GoodData.CN.
You can also choose a different database, perhaps Postgres or Snowflake, and execute your dbd project on top of it. It will do the same trick ;)
Complete code for this tutorial is available here.
The dbd tool is open-sourced under the permissive BSD license. You can find the code and documentation in the dbd repo.
