Iceberg + Spark + Trino + Dagster: modern, open-source data stack demo
I assembled the ngods (new generation open-source data stack) two months back and have used it for two projects since then.

I found that the data stack nicely scales from small data (a few GBs) to mid-size data (a few hundred GBs). It is also much cheaper than the cloud data stacks that utilize usage-based pricing (e.g., Snowflake, Redshift, or BigQuery).
I created a simple demo demonstrating its capabilities. You can use it as a starting point for your own project.
The demo is available in this GitHub repository. It retrieves selected stock symbols data history from Yahoo Finance API, stores it in a data warehouse, transforms it, and provides an analytical model for machine learning predictions and data visualizations.
The demo uses medallion architecture with three data stages: bronze, silver, and gold.

- The bronze data stage stores the data in the form of its original data source. This stage uses Apache Iceberg for data storage.
- The silver data stage stores cleaned and transformed data that blend the original data from the bronze stage. This stage also uses Apache Iceberg.
- The gold data stage implements the analytics model (dimensions, facts, etc.). I've decided to use the Postgres database for this stage.
The ngods data stack uses dbt for data transformation. The dbt executes SQL in Apache Spark for data transformations in bronze and silver stages.

The dbt must move data between the silver and gold data stages as the gold stage uses Postgres. I decided to use the Trino that maps all medallion data stages in Apache Iceberg and Postgres to schemas in one database.

The ngods use Dagster to orchestrate data warehouse initialization, stock data download, and dbt data transformation. I love Dragster's extensibility with Python code.

I built the analytics layer with cube.dev and Metabase. Cube.dev exposes a headless analytics model with dimensions and metrics.

Metabase connects to this model for data visualization (reports and dashboards).
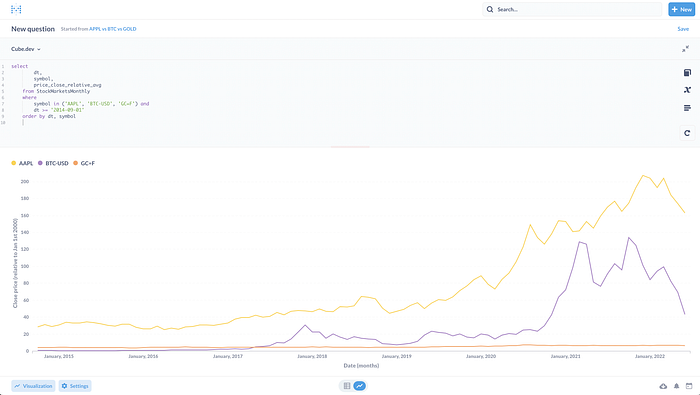
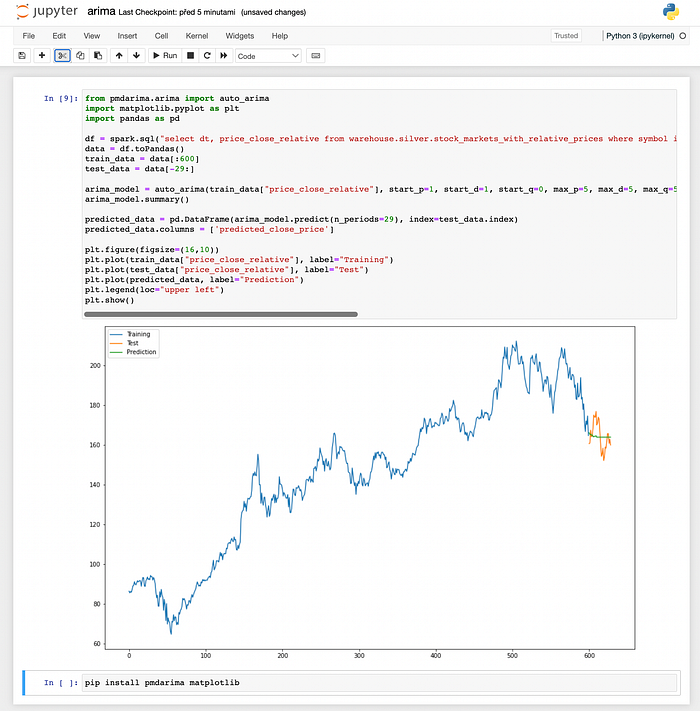
I also use Jupyter notebook for machine learning prediction of future stock trends (ARIMA time series model).
You can run this demo in a few quick steps.

